
所有网站都会有蜘蛛来爬取东西,越优秀的网站 蜘蛛越多,不过我们要区分蜘蛛 区分真伪,屏蔽一些无用的,避免养“蛛”为患。
以OKMG®为例
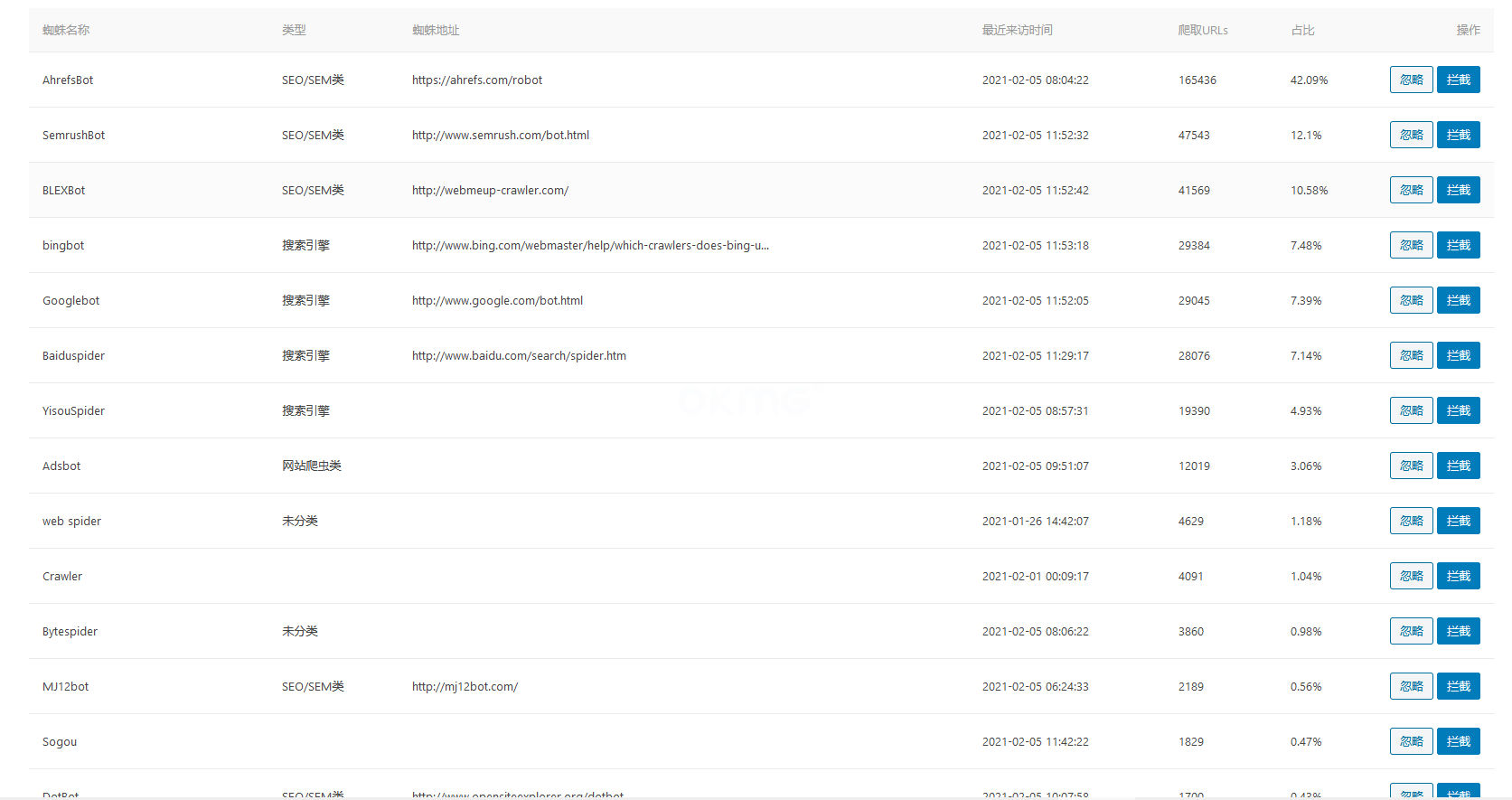
(部分数据截图)
一、AhrefsBot
AhrefsBot是什么蜘蛛?
AhrefsBot是国外网站(Ahrefs.com)的一个蜘蛛程序,那么Ahrefs是什么网站呢,这个是国外一个网络营销类的网站,有点类似于国内的5118、站长网之类,在SEO界是很有名的。AhrefsBot数据库里面有超过12万亿条链接,每天它就在不断的执行和监控Ahrefs的在线营销活动,每24小时就要访问超过60亿个网页,每15-30分钟就要更新一次索引。
根据一项调查显示,AhrefsBot是仅次于谷歌蜘蛛(Googlebot)的世界第二大活跃蜘蛛爬虫程序。
AhrefsBot对网站有什么影响?
AhrefsBot除了会轻微的增加你服务器的负担外,并不会对你的网站造成什么影响,它既不会触发网站上的广告,也不会在统计中增加流量。
对于国内的中文网站来说,AhrefsBot蜘蛛是没有什么作用的,不管是好的作用还是副作用,看到网上好多人都说 建议屏蔽点,不过芒果大叔建议 不用理会,也不用屏蔽。自然就好
二、SemrushBot
SemrushBot是SEMrush的蜘蛛爬虫。
SEMrush是一家老牌的提供搜索引擎优化数据的公司,是一个强大的、全面的在线营销竞争情报平台,其中包括 SEO、PPC、社交媒体和视频广告研究。
建议中文站屏蔽掉它的爬行,首先因为这个蜘蛛爬行并不会给网站带来流量,只会占用服务器资源,其次是这是已经数据分析公司的爬虫,它爬的数据会成为你竞争对手的分析利器。
如何屏蔽SemrushBot呢?
robots.txt文件中添加以下代码即可:
User-agent: SemrushBot
Disallow: /
User-agent: SemrushBot-SA
Disallow: /
三、BLEXBot
BLEXBot是什么蜘蛛爬虫
Blexbot是WebMeUp的蜘蛛爬虫,Blexbot每天可以抓取上百亿个页面来收集反向链接数据,并将该数据提供给其链接索引(在SEO SpyGlass中使用的链接索引)。
WebMeUp是美国的一家外链反向链接查询工具网站,他一般的形式是
Mozilla / 5.0(兼容; BLEXBot / 1.0; + http://webmeup-crawler.com/)
WebMeUp网址
https://webmeup.com/
四、bingbot
必应搜索是微软的搜索引擎,如果你不做必应的seo 屏蔽掉就好
屏蔽bingbot的方法:
User-agent: bingbot
Disallow: /
五、Googlebot
Googlebot是谷歌的搜索引擎蜘蛛,如果影响了你的服务器承受能力,且不做谷歌优化,可以屏蔽掉
六、Baiduspider
Baiduspider是百度蜘蛛呦!百度蜘蛛并不叫Baidubot的。是不是很惊讶! 相信国内99%的用户都会做百度seo吧。 千万不要手贱屏蔽掉
七、Yisouspider
Yisouspider是神马搜索的蜘蛛,
八、AdsBot
Adsbot是谷歌Google AdWords的蜘蛛,也就是广告联盟的。
九、webspider
???
十、Crawler
???
十一、Bytespider
头条搜索蜘蛛 Bytespider
首先可以非常明确的是头条搜索的爬虫 UA 为“Bytespider”首写字母为大写。
Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML,like Gecko)Chrome/41.0.6633.1032 Mobile Safari/537.36;Bytespider;bytespider@bytedance.com
随着头条搜索站长平台的上线,头条搜索蜘蛛 UA 似乎也有了一些小小的变化,将原有的邮箱换成了 https://zhanzhang.toutiao.com
//PC Mozilla/5.0 (compatible; Bytespider;[https://zhanzhang.toutiao.com/] AppleWebKit/537.36 (KHTML, like Gecko) Chrome/[70.0.0.0](http://70.0.0.0) Safari/537.36 //Android Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider; [https://zhanzhang.toutiao.com/] //IOS Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) AppleWebKit/537.36 (KHTML, like Gecko) Version/7.0 Mobile Safari/537.36 (compatible; Bytespider; [https://zhanzhang.toutiao.com/]
头条搜索 ip 字段介绍
头条搜索的 ip 字段总共涉及 6 个,具体字段如下:
110.249.201.0/24 110.249.202.0/24 111.225.148.0/24 111.225.149.0/24 220.243.135.0/24 220.243.136.0/24
头条搜索蜘蛛基本工作流程
1.抓取网页。每个独立的搜索引擎都有自己的网页抓取程序爬虫(Spider)。爬虫顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
2.处理网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。
3.提供检索服务。用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和 URL 外,还会提供一段来自网页的摘要以及其他信息。
其它
如果您的网站发现有头条 spider 的 UA“Bytespider”抓取存在抓取量过大,导致您的网站出现缓慢、挂掉等问题,等到后期头条搜索站长平台正式上线后,就可以通过“抓取频次”功能,对网站进行设置抓取要求,官方称会在 1 天内时间内生效。同时关于 Bytespider 头条搜索还可以向 zhanzhang@bytedance.com 邮箱获取联系。
十二、MJ12bot
MJ12bot 是英国的一家老牌的搜索引擎营销网站 Majestic 的爬虫,他有专门的中文站,对外链查询等很多 SEO 数据查询提供数据支撑,做过外链的都知道,获取外链资源是一项基本能力,这个网站可以查询网站的外链资源数,不过很多公司看到日志里有这个 MJ12bot 蜘蛛,中文是选择直接屏蔽掉(MJ12bot 是 Majestic-12 分布式搜索引擎的爬虫)
官方网址:https://zh.majestic.com/
官方给了一个修改 robots 的方法,就是在 robots.txt 文件中加入:
User-agent:MJ12bot Disallow:/
对于MJ12bot 爬虫蜘蛛要看抓取次数是否很多,如果抓取次数很多,而且网站访问速度有所降低的话,就屏蔽掉,另外这种还有可能是其他采集软件伪装的搜索引擎制作,通过 nslookup 反查一下 IP 地址,如果是采集软件伪装的蜘蛛,立马封掉。
十三、Sogou
搜狗蜘蛛
十四、DotBot
DotBot是什么蜘蛛爬虫?如何禁止DotBot抓取
DotBot是Moz的网络爬虫程序,Moz旗下链接分析网站opensiteexplorer专门用来分析网站SEO外链数据,BotBot蜘蛛爬虫就是为Moz服务,在互联网上抓取大量的网页进行各种数据分析。
如果我们不希望Dotbot抓取自己的网站,可以使用robots.txt进行评比。DotBot遵robots.txt协议。
DotBot蜘蛛爬虫原型
Moz蜘蛛爬虫UA:"Mozilla/5.0 (compatible; DotBot/1.1; http://www.opensiteexplorer.org/dotbot, help@moz.com)"
网站如何禁止DotBot抓取
在我们的网站根目录中的robots.txt文件中写上如下代码:
User-Agent: DotBot
Disallow: /
十五、Applebot
Applebot 是 Apple 推出的网络爬虫工具。“Siri 建议”和“聚焦建议”等产品均使用 Applebot。这个工具遵循惯用的 robots.txt 规则和 robots 元标签,并且源自 17.0.0.0 网络块。
识别 Applebot
用户代理字符串包含“Applebot”和其他代理信息。示例如下:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Applebot/0.1)
Applebot 还支持以下指令:
- noindex:Applebot 不会针对相关页面创建索引,并且相关页面不会出现在“聚焦建议”或“Siri 建议”中。
- nosnippet:Applebot 不会生成页面描述或网页答案。所有示意访问相关 URL 的建议都仅包含页面的标题。
- nofollow:Applebot 不会追踪页面上所示的任何链接。
- none:如上所述,Applebot 不会针对页面创建索引、生成片段或追踪页面上所示的链接。
- all:Applebot 会针对建议提供文稿并生成内容片段,以便在具有代表性的图片旁边显示有关页面的简短描述。Applebot 可能会追踪页面上所示的链接,以提供更多建议。
十六、CCbot
一. CCbot是什么蜘蛛?
CCbot,全称为Common Crawl Bot,是一个非营利性基金会致力于提供可以被所有人访问和分析的Web爬网数据的开放存储库。
二. 你如何处理CCbot蜘蛛?
方法1. 使用robots.txt
使用robots.txt文件来允许或禁止蜘蛛访问页面的权限。robots.txt是放在网站根目录中,蜘蛛来访问时会先查找并查看robots.txt文件,并遵守robots协议来访问网站上的内容,允许访问则访问,不允许访问蜘蛛则离开。
①. 不允许任何蜘蛛访问您站点的任何部分
User-agent:*
Disallow:/
②. 允许任何蜘蛛访问您站点的任何部分
User-agent:*
Disallow:
③. 不允许CCbot蜘蛛访问网站的任何部分
User-agent:ccbot
Disallow:/
④. 允许CCbot蜘蛛访问您站点的任何部分
User-agent:ccbot
Disallow:
⑤. 允许CCbot蜘蛛访问您站点,但不允许CCbot访问“wp-admin”文件夹
User-agent:ccbot
Disallow:/wp-admin
方法2. 使用元标记
可以在页面中使用元标记来帮助控制搜索引擎蜘蛛对您网站的访问权限。如果您为所有页面使用模板,则可以在和之间添加元标记, 它将适用于使用该模板的所有页面。如果要控制特定页面,可以在和之间的各个页面上添加元标记 。
①. 允许所有蜘蛛访问您的页面
②. 允许所有蜘蛛访问您的网页并跟踪页面上的链接
③. 允许所有蜘蛛访问您的网页,但不允许他们跟踪链接
④. 不允许任何蜘蛛访问您的网页
⑤. 允许CCbot访问您的网页
⑥. 不允许CCbot访问您的页面
⑦. 允许CCbot访问您的页面并跟踪更多页面的链接
十七、360Spider
360搜索蜘蛛
十八、PetalBot
PetalBot-华为自研搜索引擎,这个蜘蛛就是花瓣蜘蛛,将来或许也会在国内再杀出一个搜索引擎
如何阻止 PetalBot 访问您的站点
PetalBot 符合 Internet 机器人协议。您可以使用 robots.txt 文件完全阻止 PetalBot 访问您的网站,或阻止 PetalBot 访问您网站上的某些文件。
PetalBot 带给 Web 服务器多少压力
为了获得对目标资源更好的检索结果,PetalBot 需要保持一定程度的网站爬网。我们力求不给网站带来不合理的负担,我们将根据服务器容量,网站质量和网站更新等综合因素进行调整。如果 PetalBot 的访问有任何不合理的行为,请将您的疑虑发送至 search@aspiegel.com。
如何判断 PetalBot 爬行
您可以验证访问您的服务器的 Web 爬网程序是否真的是 PetalBot。
验证 PetalBot 为呼叫者:
1.使用 host 命令在日志访问 IP 地址上运行反向 DNS 查找。
2.验证域名在 aspiegel.com 中。
3.使用在检索到的域名上的主机命令,对在步骤 1 中检索到的域名运行正向 DNS 查找。验证它是否与日志中的原始访问 IP 地址相同。
十九、YandexBot
俄罗斯搜索巨头Yandex的蜘蛛,
二十、Nimbostratus-Bot
???
二十一、VelenPublicWebCrawler
???
二十二、Facebot
???
二十三、DuckDuckGo Favicons Bot
DuckDuckGo Favicons Bot是DuckDuckGo的爬虫
DuckDuckGo是美国的一个互联网搜寻引擎,其总部位于美国宾州Valley Forge市。
一般默认的形式是 Mozilla/5.0 (compatible; DuckDuckGo-Favicons-Bot/1.0; +http://duckduckgo.com)” – 0.047 0.047
传统搜索引擎为了优化搜索结果,必须对用户数据进行尽量全面的收集和分析,这是对用户隐私的一种侵犯。而 DuckDuckGo 则成功地避开了这样的缺陷。在 DuckDuckGo 的隐私政策中非常明确的声明网站不会记录用户的浏览器 UA、IP 地址、搜索行为等任何相关数据,默认情况下也不会使用 Cookie 来记录数据。此外,DuckDuckGo 还对用户点击搜索结果后跳转到目标网页的过程进行了重定向处理,目标网站无法获知用户是通过输入哪些搜索词跳转到自己的网站。这进一步保护了用户的隐私安全。同时,DuckDuckGo 鼓励用户使用 Firefox 浏览器的强制 https 扩展和 Tor 匿名网络等方式来保护自己的隐私,而 DuckDuckGo 自身也运营着一个 Tor 的跳出节点,以便用户在使用相对速度较慢的 Tor 匿名网络时也能够快速而安全地访问 DuckDuckGo 进行搜索。
二十四、spider
???
二十五、TprAdsTxtCrawler
???
二十六、Seekport Crawler
是http://www.seekport.com/的蜘蛛,具体干啥没看。
二十七、MTRobot
???
二十八、yacybot
http://yacy.net/的蜘蛛
二十九、Linespider
https://lin.ee/ 不知道啥玩意,网站ssl到期打不开
三十、oBot
https://www.xforce-security.com/crawler/ IBM
IBM我们使用多台计算机对网页进行爬网,并使用大型计算机集群对网页内容进行分类。此分析的结果是一个紧凑的webfilter数据库,该数据库可在多个内容过滤产品(包括针对OEM合作伙伴的SDK)中提供给我们的客户。使用几种算法,我们可以分配超过65个不同的类别(https://exchange.xforce.ibmcloud.com/faqurlu categoriesu列表)到网页。
三十一、linkdexbot
www.linkdex.com/bots/蜘蛛
三十二、Web-Crawler
???
三十三、JobboerseBot
???
三十四、DataForSeoBot
???
三十五、SurdotlyBot
sur.ly/bot.html的蜘蛛
三十六、DingTalkBot
钉钉
三十七、DiscoverBot
???
三十八、SabsimBot
???
三十九、SMTBot
http://www.similartech.com/smtbot蜘蛛
加问好的部分几个蜘蛛是不知道的!如果你知道 欢迎评论补充!



评论(0)